
Our MagicMix allows mixing of two different semantics to create a novel concept.
Abstract
Have you ever imagined what a watermelon-alike lamp or a tiger-alike rabbit would look like? In this work, we attempt to answer these questions by exploring a new task called semantic mixing, aiming at mixing two different semantics to create a new concept (e.g., raccoon and coffee machine). Unlike style transfer where an image is stylized according to the reference style without changing the image content, semantic mixing blends two different concepts in a semantic manner to synthesize a novel concept while preserving the spatial layout and geometry. To this end, we present MagicMix, a simple yet effective solution based on pre-trained text-conditioned diffusion models. Motivated by the progressive property of diffusion models where layout/ shape emerges at early denoising steps while semantically meaningful details appear at later steps during the denoising process, our method first obtains a coarse layout (either by corrupting an image or denoising from a pure Gaussian noise given a text prompt), followed by switching the conditional prompt to the second concept for semantic mixing. Our method does not require any spatial mask or re-training, yet is able to synthesize novel objects (e.g., a watermelon-alike lamp) with high fidelity. With our method, we present our results over diverse downstream applications, including semantic style transfer, novel object synthesis, breed mixing, and concept removal, demonstrating the flexibility of our method.
Semantic Mixing
Semantic mixing refers to the task of mixing two different semantics to create a new concept.
(Hover mouse to reveal the generated results).







Mini Game
We challenge the viewer to guess the involved concepts behind the generated image. Hover mouse to reveal the answer


+ lamp


+ electric fan


+ coffee machine


+ grapes


+ bag


+ purse


+ vinyl

+ cat
Concept removal
Image concept can be removed to generate an image with similar layout but with completely different content.
(Hover mouse to check out the concept removed outputs)

remove dumpling


remove shell

remove dog


remove hamburger


remove watermleon


remove cat


remove pumpkin

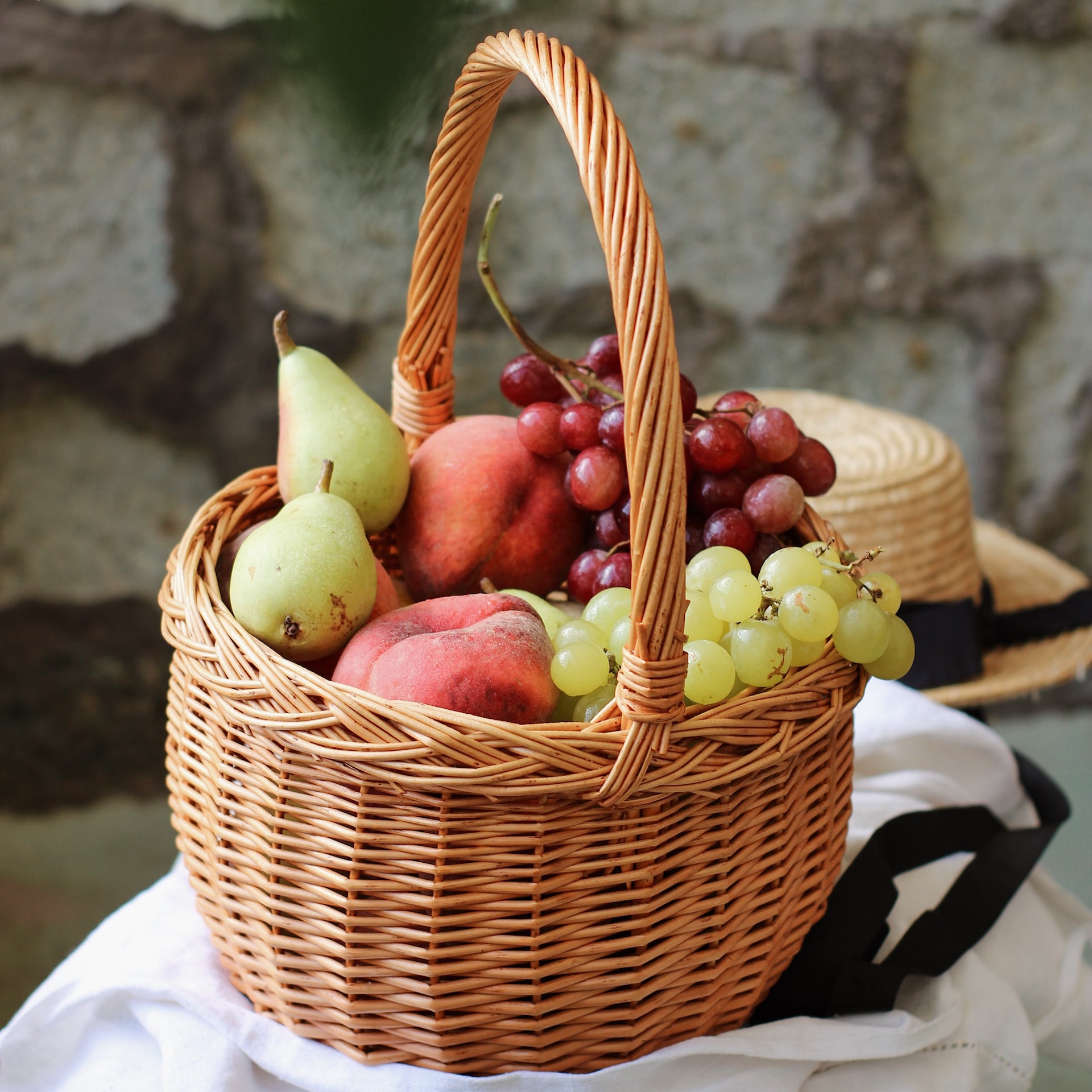
remove basket

More Results
Semantic style transfer

Novel object synthesis
Breed mixing

Concept removal

Paper

MagicMix: Semantic Mixing with Diffusion Models
Jun Hao Liew*, Hanshu Yan*, Daquan Zhou and Jiashi Feng
arXiv, 2022. (*equal contribution)
@article{liew2022magicmix,
title = {MagicMix: Semantic Mixing with Diffusion Models},
author = {Liew, Jun Hao and Yan, Hanshu and Zhou, Daquan and Feng, Jiashi},
journal = {arXiv preprint arXiv:2210.16056},
year = {2022},
}Acknowledgements
This template was originally made by Phillip Isola and Richard Zhang for a colorful project, and inherits the modifications made by Jason Zhang and Elliott Wu.